Dies ist ein Essay zur prinzipiellen Fehlerhaftigkeit von Computer-Programmen …
Wäre das Programmieren ein strikt deterministischer Prozeß, der nach festen Regeln abläuft, so wäre es bereits seit langem automatisiert worden. (Niklaus Wirth)
„Jedes Programm hat mindestens einen Fehler“, …
… dieser Satz, der von manchen als „Hauptsatz der Informatik“ angesehen wird, wird bei vielen Nicht-Computer-Experten Verwunderung auslösen. Schließlich sind Computer-Programme universell im Einsatz und weder ein Handy noch ein Atomkraftwerk funktionieren ohne eine Vielzahl von und das komplexe Zusammenspiel einzelner Programme. Da kann es doch kaum sein, dass all diese Programme noch mindestens einen Fehler enthalten.
Gibt man den Satz „Jedes Programm hat mindestens einen Fehler“ (einschließlich der Anführungsstriche) bei Google ein, dann stellt man fest, dass deutlich mehr als 10.000 Webseiten diesen Satz zu Programm und Fehler enthalten.
Das ist erstaunlich, denn der Satz hat 6 Worte und es ist normalerweise nicht möglich, einen beliebigen Satz aus 6 Worten zu bilden, der überhaupt Einträge liefert.
Bei dem Satz „Jedes Programm hat mindestens einen Fehler“ muss es sich also um ein geflügeltes (Sprich-)Wort handeln; ob es allerdings ein Informatik-Witz (wie die obersten Google-Ergebnisse nahelegen) oder eine zutreffende Aussage über Computer, Algorithmen und ihre Problemlösungsfähigkeit beinhaltet, muss eine eingehende Untersuchung zeigen.
Was ist eigentlich ein Programmfehler?
Um die Definition von Programm braucht man sich weniger Gedanken zu machen, als um die Definition von Fehler. Programme sind die Bestandteile von Software und Software benötigt immer eine bestimmte Hardware, um überhaupt wirksam zu werden. Computer sind also von Menschen geschaffene Systeme, die eine materielle Basis benötigen, in denen Daten gemäß vordefinierten Regeln eingegeben, verarbeitet, gespeichert und ausgegeben werden. So gesehen ist jedes Telefon und jedes Atomkraftwerk (auch) ein Computer. Tendenziell geht die Entwicklung dahin, dass es kaum noch einen von Menschen geschaffenen materiellen Gegenstand gibt, der nicht Programme enthält, die auch fehlerhaft sein könnten bzw. gemäß dem oben beschriebenen „Hauptsatz der Informatik“ fehlerhaft sind.
Um zu einer Definition von Fehler zu kommen, muss man sich mit der Entwicklung und Konzeption von Computern beschäftigen, insbesondere mit der Frage, wie die Software entwickelt wird. Ein populäres Lexikon wie Wikipedia beschäftigt sich sehr eingehend mit der Frage nach den Fehlern in Computer-Software und wie sie zustande kommen können.
Quelle: https://de.wikipedia.org/wiki/Programmfehler, abgerufen bereits vor längerer Zeit; Text wurde zur besseren Lesbarkeit von mir modifiziert, gekürzt und umformatiert. Da hier recht ausgiebig zitiert wird, stelle ich diesen ganzen Blogbeitrag unter dieselbe Lizenz wie die Wikipedia. Dieser Text basiert auf diesem und weiteren Artikeln aus der freien Enzyklopädie Wikipedia und steht unter der Lizenz Creative Commons CC-BY-SA 3.0 Unported
Ein Programmfehler oder Softwarefehler, häufig auch als Bug bezeichnet, ist ein Fehlverhalten von Computerprogrammen. Dieses Fehlverhalten tritt auf,
- wenn der Programmierer einen bestimmten Zustand in der Programmlogik beim Umsetzen der Vorgaben nicht berücksichtigt hat, oder
- wenn die Laufzeitumgebung fehlerhaft arbeitet. Weiterhin können auch
- Unvollständigkeit,
- Ungenauigkeit oder
- Mehrdeutigkeiten in der Spezifikation des Programms zu Fehlern führen. In der Praxis treten Computerprogramme ohne Programmfehler selten auf. Statistische Erhebungen in der Softwaretechnik weisen im Mittel etwa zwei bis drei Fehler je 1.000 Zeilen Code aus.
In der Softwaretechnik wird zwischen folgenden Typen von Fehlern in Programmen unterschieden:
- Syntaxfehler sind Verstöße gegen die grammatischen Regeln der benutzten Programmiersprache. Ein Syntaxfehler verhindert die Kompilierung des fehlerhaften Programms. Bei Programmiersprachen, die sequentiell interpretiert werden (Programme für Interpreter), bricht das Programm an der syntaktisch fehlerhaften Stelle ab.
- Laufzeitfehler sind alle Arten von Fehlern, die auftreten, während das Programm abgearbeitet wird. Da diese Fehler die Programmlogik und damit die Bedeutung des Programmcodes betreffen, spricht man hier auch von semantischen Fehlern. Ihre Ursache liegt in den meisten Fällen in einer
- inkorrekten Implementierung der gewünschten Funktionalität im Programm. Gelegentlich tritt als Ursache auch eine
- ungeeignete Laufzeitumgebung auf (z. B. eine falsche Betriebssystem-Version).
- Wird in Programmiersprachen ohne automatische Speicherbereinigung (etwa C oder C++) Speicher nach der Verwendung nicht mehr freigegeben, so wird durch das Programm auf Dauer immer mehr Speicher belegt. Diese Situation wird Speicherleck genannt. Aber auch in Programmiersprachen mit automatischer Speicherbereinigung (etwa Java oder C#) können ähnliche Probleme auftreten, wenn zum Beispiel Objekte durch systemnahe Programmierung unkontrolliert angesammelt werden.
- Noch kritischer sind versehentlich vom Programmierer freigegebene Speicherbereiche, die oft trotzdem noch durch hängende Zeiger referenziert werden, da dies zu völlig unkontrolliertem Verhalten der Software führen kann. Des Weiteren gibt es auch
- Bugs im Zusammenhang mit Multithreading, etwa Race Conditions, welche Konstellationen bezeichnen, in denen das Ergebnis einer Operation vom zeitlichen Verhalten bestimmter Einzeloperationen abhängt, oder Deadlocks.
- Fehler im Compiler, der Laufzeitumgebung oder sonstigen Bibliotheken. Solche Fehler sind meist besonders schwer nachzuvollziehen, da das Verhalten des Programms in solchen Fällen nicht seiner Programmlogik entspricht. Insbesondere von Compiler und Laufzeitumgebung wird daher besondere Zuverlässigkeit erwartet, welche jedoch gerade bei kleineren Projekten nicht immer gegeben ist.
- Logische Fehler und semantische Fehler bestehen in einem falschen Problemlösungsansatz, beispielsweise auf Grund eines Fehlschlusses oder eines fehlerhaften oder falsch interpretierten Algorithmus.
- Designfehler sind Fehler im Grundkonzept, entweder bei der Definition der Anforderungen an die Software, oder bei der Entwicklung des Softwaredesigns, auf dessen Grundlage das Programm entwickelt wird.
- Fehler bei der Anforderungsdefinition beruhen oft auf mangelnder Kenntnis des Fachgebietes, für das die Software geschrieben wird oder auf Missverständnissen zwischen Nutzern und Entwicklern.
- Fehler direkt im Softwaredesign hingegen sind oft auf mangelnde Erfahrung der Softwareentwickler oder auf Folgefehler durch Fehler in der Anforderungsspezifikation zurückzuführen. In anderen Fällen ist das Design historisch gewachsen und wird mit der Zeit unübersichtlich, was wiederum zu
- Designfehlern bei Weiterentwicklungen des Programms führen kann. Vielen Programmierern ist das Softwaredesign auch lästig, sodass oftmals
- ohne richtiges Konzept direkt entwickelt wird, was dann insbesondere bei steigendem Komplexitätsgrad der Software unweigerlich zu Designfehlern führt. Sowohl für Fehler in der Anforderungsdefinition als auch im Softwaredesign kommen darüber hinaus vielfach Kosten- oder Zeitdruck in Frage. Ein typischer Designfehler ist die
- Codewiederholung, die zwar nicht unmittelbar zu Programmfehlern führt, aber bei der Softwarewartung, der Modifikation oder der Erweiterung von Programmcode sehr leicht übersehen werden kann und dann unweigerlich zu unerwünschten Effekten führt.
- Fehler im Bedienkonzept. Das Programm verhält sich anders als es einzelne oder viele Anwender erwarten, obwohl es technisch an sich fehlerfrei arbeitet.
- Fehler infolge der Betriebsumgebung. Verschiedenste Begebenheiten wie elektromagnetische Felder, Strahlen, Temperaturschwankungen, Erschütterungen, usw., können auch bei sonst einwandfrei konfigurierten und innerhalb der Spezifikationen betriebenen Systemen zu Fehlern führen. Fehler dieses Typs sind sehr unwahrscheinlich, können nur sehr schwer festgestellt werden und haben bei Echtzeitanwendungen unter Umständen fatale Folgen. Sie dürfen aber aus statistischen Gründen nicht ausgeschlossen werden. Das berühmte „Umfallen eines Bits“ im Speicher oder auf der Festplatte auf Grund der beschriebenen Einflüsse stellt zum Beispiel solch einen Fehler dar. Da die Auswirkungen eines solchen Fehlers (z.B. Absturz des Systems oder Boot-Unfähigkeit, weil eine Systemdatei beschädigt wurde) von denen anderer Programmfehler meist nur sehr schwer unterschieden werden können, vermutet man oft eine andere Ursache, zumal ein solcher Fehler häufig nicht reproduzierbar ist. (Ende Wikipedia) OK
Fehler innerhalb der Stufen der Software-Entwicklung und Fehler auf den Stufen der Software-Umsetzung
Aus den Überlegungen der Wikipedia-Autoren, die eher unsystematisch wirken, wird deutlich, dass auf jeder Stufe der Software-Entwicklung Fehler auftreten können. Fehler sind auch zu erwarten, wenn man die Basis-Software (Programmiersprachen, Compiler, Interpreter, Maschinensprache) ungeprüft lässt. Denn ein fertigen Computer-Programms bedarf zu seiner Umsetzung Bearbeitungsschritte, die von einer höheren Stufe der Programm-Logik bis hinunter zu den einzelnen Bits der Computer-Hardware führen, die nur mit Maschinen-Befehlen verändert werden können.
Jedes Computer-Programm ergibt sich aus einer Problem-Analyse beim Auftraggeber, die von einem „System-Analytiker“ hin zu einer Programm-Spezifikation entwickelt wird. Auf Basis der Programm-Spezifikation wird dann ein Computer-Algorithmus entwickelt, der schon sehr stark formalisiert ist (Darstellung mittels Programm-Ablaufplan oder Struktogramm). Selbst wenn die Spezifikation und der Algorithmus fehlerfrei sind, könnte noch bei der Übertragung in eine Programmiersprache, deren Anwendung auf einen Compiler oder Interpreter und schließlich bei der Umsetzung der Programm-Befehle in Maschinencode Fehler auftreten, wenn die jeweils tiefere Schicht der Programmumsetzung schichtenspezifische Fehler enthält.
Schließlich können – selbst wenn alle bisher genannten Komponenten fehlerfrei waren – immer noch einzelne Bits bei der Programmausführung „umfallen“ und damit nicht reproduzierbare Fehler produzieren.
Der zuletzt genannte Fehlertyp ist natürlich kaum in den Griff zu bekommen. Auf den anderen Stufen der Programm-Umsetzung ist aber vorstellbar, dass man Fehler systematisch ausschließt, indem man die Programmlogik auf ein sicheres Fundament zurückführt. Als ein solches sicheres Fundament zur „Verifikation“ (Nachweis der Richtigkeit) gilt die Mathematik. Es gibt Verfahren der Programm-Verifikation, bei denen man jeden formal geschriebenen Algorithmus auf Sätze der Mathematik zurückführen kann. Gelingt dann der Beweis dieser Sätze, dann sind auch die zugrundeliegenden Algorithmen fehlerfrei.
 Vgl. zum folgendem:
Vgl. zum folgendem:
Heinz Peter Gumm, Manfred Sommer:
Einführung in die Informatik,
Oldenbourg Wissenschaftsverlag; Auflage: vollständig überarbeitete 9. Auflage 2011
ab Seite 183
Nachweis der Fehlerfreiheit von einzelnen Programmschritten?
Nach der Vorstellung der Autoren ist jeder Computer-Algorithmus aus Teilschritten aufgebaut, die jeder für sich elementar sind. So werden Daten eingelesen, in eine Formel eingesetzt und die Ergebnisse werden ausgegeben. Diese elementaren Operationen (Hintereinander-Ausführen, Rechnen, Speichern, Ein- und Ausgabe) erscheinen für mathematische Beweisführungen recht gut verfügbar. Schwierigkeiten machen schon eher die Verzweigungen (je nach Fall müssen unterschiedliche Programm-Teile ausgeführt bzw. angesprungen werden). Noch schwieriger sind die Schleifen einzuschätzen: Ein Programm-Teil muss in Abhängigkeit einer Bedingung durchlaufen werden, zugleich muss eine Variable so verändert werden, das irgendwann einmal die Schleife auch verlassen werden kann.
Für die Beispiele, die Gumm und Sommer verwenden, werden zunächst nur ganzzahlige Speichervariablen zugelassen. Ob dies eine zu starke Einschränkung ist, wird sich noch zeigen müssen. Für den kaufmännischen Bereich (Rechnen mit Dezimalzahlen, deren Endergebnisse jeweils auf wenige Nachkommastellen gerundet werden), scheint diese Einschränkung auf ganze Zahlen akzeptabel, denn man kann sich durch Komma-Verschiebungen und strikte Rundungen gut vorstellen, dass sämtliche kaufmännischen Rechenvorgänge eineindeutig auf den Bereich der ganzen Zahlen abbildbar ist.
Die Argumentation von Gumm und Sommer ist so zu verstehen, dass man jedes Computer-Programm auf einen Algorithmus zurückführen kann, der nur sehr beschränkte Möglichkeiten hat, einzelne Bausteine zu verwenden. Es sind dies hier die schon oben angesprochenen Bausteine Hintereinander-Ausführen, Wertzuweisung oder Rechnung mit bestimmten Grundoperationen (zu denen in erster Linie die Grundrechenarten gehören), Verzweigung, Schleife.
Was bei Gumm und Sommer fehlt, ist der Aufruf von Unterprogrammen. Sollte dieser Schritt als mathematisch trivial angesehen werden? Programmierern ist zumindest bekannt, dass beim Aufruf von Unterprogrammen bestimmte Fehler unbedingt auszuschließen sind. Insbesondere darf in einen Unterprogramm kein Zugriff auf andere Unterprogramme oder gar das Hauptprogramm erfolgen. Des Weiteren wäre zu fragen, welche Relevanz die Wertübergabe vom Haupt- auf das Unterprogramm und die Wertrückgabe vom Unter- zum Hauptprogramm für Programmfehler haben könnte. Hier gibt es nämlich unterschiedliche Handhabung von Referenzparametern, die in der Praxis des Programmierens hohe Bedeutung haben.
Algorithmen arbeiten nur mit relativ wenigen Grundkonzepten, auch komplexe Algorithmen werden aus einfachen Grundbausteinen zusammengesetzt. Man muss also nur das Programm bzw. den zugrundeliegenden Algorithmus solange aufspalten bis ausschließlich elementare Grundbausteine übrig bleiben. Für diese sind dann mathematische Beweise zu formulieren. Schwierig ist dies insbesondere bei Schleifen. Hier wird eine sogenannte Invariante benötigt, die einerseits den Einstieg in die Schleife erlaubt, die aber auch zugleich sichern soll, dass die Schleife irgendwann mal beendet wird.
Hat man aber für alle Grundbausteine eines Algorithmus` den mathematischen Nachweis geführt, dann müsste das darauf aufbauende Programm ohne Fehler sein.
Gegen diese „schlichte“ Argumentation können verschiedene Einwände vorgebracht werden:
- Komplexitätsproblem: Möglicherweise sind alle einzelnen Bausteine korrekt, doch ihr Zusammenwirken entfaltet so viele komplexe Möglichkeiten, dass sich die Fehlerfreiheit wieder verliert. Um dieses Gegenargument zu verdeutlichen, möchte ich auf eine Analogie zurückgreifen: Wettervorhersage. Jede einzelne Komponente, die das Wetter bestimmt, ist elementar beschreibbar. Trotzdem sind viele Wettervorhersagen schon nach wenigen Tagen falsch. Der Grund liegt wohl darin, dass geringe Veränderungen in den Ausgangsbedingungen sich in den Wettermodellen so schnell entfalten, dass die Prognose-Kraft schnell gegen Null tendiert.
- Laufzeitproblem: Der Algorithmus ist zwar ohne Fehler, er terminiert auch (das Programm ist „irgendwann“ fertig und liefert dann die richtigen Ergebnisse), doch das Programm läuft länger als die Menschheit warten kann. Der Fehler ist, dass das Programm nicht genutzt werden kann. Beispiele für Algorithmen, die das Laufzeitproblem nach sich ziehen, findet man unter dem Stichwort „Problem des Handlungsreisenden„.
- Fehler auf vorherigen Stufen der Programm-Entwicklung.
Notwendige Fehler während der Programm-Entwicklung
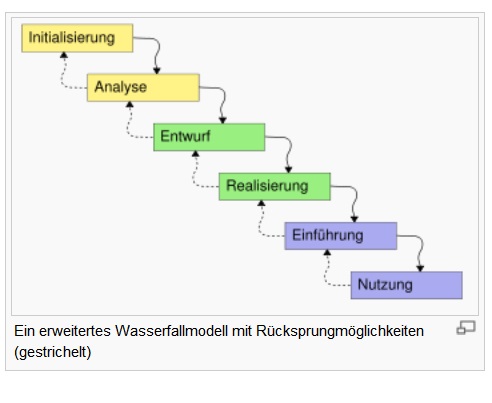
Bevor ein Algorithmus so formuliert ist, dass auf ihn ein Verfahren der Verifikation angewandt werden kann, muss dieser Algorithmus entwickelt werden. Dafür sind mehrere Verfahrensschritte erforderlich. In der Praxis und in der universitären Lehre zur Programm-Entwicklung wird gerne auf das „Wasserfall-Modell“ der Software-Entwicklung zurückgegriffen, wobei in modernen Darstellungen das Wasser auch den Weg zurück finden muss, wenn auf einer niedrigen Stufe Fehler gefunden werden, die mit ihren jeweiligen Methoden nicht zu bekämpfen sind.
Auch hier greife ich auf die Wikipedia zurück, um das Wasserfall-Modell der Software-Entwicklung zu skizieren.
Phasen der Software-Entwicklung
Eine andere Variante macht daraus sechs Schritte:
https://de.wikipedia.org/wiki/Wasserfallmodell (Text aus Wikipedia, verändert und formatiert von mir) Diese Art der Software-Entwicklung nicht mehr ganz zeitgemäß. Software ist heutzutage kein Maßanzug mehr, der für einen einzelnen Kunden angefertigt wird. Software-Entwicklung ist Massen-Konfektion, die aber das jeweilige Kaufprodukt noch auf die individuellen Bedürfnisse des Kunden anpasst (Beispiel SAP). Bei der üblichen Standard-Software für Arbeitsplatz-Rechner (Personal-Computer) muss diese Anpassungsleistung vom Endanwender selbst vorgenommen werden. Es sollte klar sein, dass das Hinzunehmen dieses Schritts (Software-Anpassung auf individuelle Bedürfnisse) das Problem der Fehlerfreiheit der Programme nicht vereinfacht. Denn ein falscher Problemlösungsansatz (siehe Fehler 4 der Wikipedia-Liste ganz oben) kann auf der Anwenderebene nicht korrigiert werden. Ob eine Programm-Funktion ein Fehler oder eine Funktion ist, kann auf der Ebene der Endanwender oft nicht unterschieden werden. So haben mache Anwender den Wunsch nach einem Layout-Programm, um ihre Texte und Grafiken optimal miteinander zu verbinden. Erwerben sie zur Lösung ihres Problems allerdings das Programm Word aus dem Hause Microsoft, dann werden sie mit etlichen Teilproblemen zu kämpfen haben. Denn Word ist ein Textverarbeitungsprogramm, das die Dominanz des Textes gegenüber Grafik auch gegen den Willen des Programm-Nutzers erzwingt. Dass dies zwar den Endanwendern und wohl auch den Software-Entwicklern von Word bekannt ist, schließt nicht aus, dass die Marketing-Abteilung von Microsoft davon nichts wissen will. Dieser Fehler kann aber nicht dem Programm angeheftet werden. Manche fassen die ersten Schritte (vor der formalen Algorithmus-Bestimmung) unter den Stichworten „Entwurf und Design“ zusammen und stellen knapp und bündig drei Forderungen auf: „Die Anforderungen des Kunden müssen vollständig, widerspruchsfrei und prüfbar festgehalten werden.“ (Quelle: http://www.projekthandbuch.de/it_model_swe_requirements.htm) Mit dieser Forderung wird von Programmentwicklung ein Standard eingefordert, wie er auch in den Wissenschaften für die Erklärungskraft von Theorien verlangt wird. An einen Beispiel soll aufgezeigt werden, dass in diesen ersten Stufen der Programm-Entwicklung Abstraktionen unvermeidlich sind, die Fehler in den Programmen mit hoher Wahrscheinlichkeit nach sich ziehen müssen. Kunde und Auslöser der Software-Entwicklung ist ein kommerziell agierenden Unternehmen, das wissen möchte, welche Produkte es produzieren soll, damit es langfristig am Markt überleben und zugleich für die Eigentümer Profite erwirtschaften kann. Das Programm soll diese Produkte benennen, die Kosten und die Umsätze für diese Produkte sollen bestimmt werden. Bei der Programm-Entwicklung würde man hingehen und zunächst eine IST-Analyse durchführen: Welche Produkte werden gegenwärtig angeboten, welche Kosten und welche Erträge werfen diese Produkte gegenwärtig ab? Bereits zur Umsetzung dieser Anforderung müssen schwerwiegende Entscheidungen getroffen werden, denn die Detailinformationen zu den Kosten müssen genau wie die Detailinformationen zu den Umsätzen den einzelnen Produkten zugeordnet werden. Da das Unternehmen aber mehrere Produkte im Angebot an, muss bis hinein in die einzelnen Arbeitsabläufe der Mitarbeiter analysiert werden, in welchem Umfang und mit welcher Intensität sie für die jeweiligen Produkte tätig sind. Das wird nur gehen, wenn man ab einer gewissen Stufe der Detailliertheit den Prozess der Analyse abbricht und sich für eine Zuordnung der Kosten für die Arbeit der Mitarbeiter zu den einzelnen Produkten entscheidet. Bricht man hier zu früh ab, dann ist die Zuordnung fehlerhaft und alle darauf aufbauenden Schlussfolgerungen sind Makulatur. Abgesehen von diesem Detail-Differenzierungsproblem gibt es noch das Prognose-Problem: Die Unternehmensleitung möchte wissen, welche Produkte in Zukunft zu produzieren sind. Das hängt aber unter anderen auch davon ab, wie sich die Umsätze und die Kosten in Zukunft entwickeln werden. Da die Zukunft aber prinzipiell offen – also unbekannt ist, können diese Werte nur geschätzt, also nicht berechnet werden. Wie gut solche Wahrscheinlichkeitsaussagen sein können, ist höchst umstritten. FazitDie vorliegenden Überlegungen lassen eine durchgängige Skepsis gegenüber fehlerfreien Programmen erkennen. Trotzdem ist es hilfreich, über die Fehlerfreiheit von Software nachzudenken. Insbesondere die Überlegungen, wie man Programm-Algorithmen auf elementare Bestandteile zurückführt, deren Fehlerfreiheit mittels Mathematik überprüfbar gemacht wird, sind hilfreich, um Fehler auf unteren Programmstufen und beim Weg des Programms zum Maschinen-Programm auszuschließen. Hilfreich ist aber auch die Erkenntnis, dass weiter oben (bei der System-Entwicklung) Situationen vorliegen, die für eine perfekte Programm-Umsetzung zu komplex sind. Das ist auch tröstlich, denn das schließt auf absehbare Zeit perfekte Programme aus, die den Menschen mit absoluter Sicherheit sagen, was sie zu tun haben. Die prinzipielle Fehlerhaftigkeit von Computer-Programmen ist also auch ein Garant der menschlichen Freiheit.
|