

Vor und nach dem Liken Facebook
Viele Internetnutzer des sozialen Netzwerks Facebook liken gerne. Das heißt, sie geben innerhalb oder außerhalb von Facebook eine Bewertung ab, die innerhalb des Netzwerkes dokumentiert wird (vgl. Ausschnitt meiner Facebook-Webseite vor und nach einem Like für ein Gomera-Foto). Die Nutzer denken, sie handeln spontan und man könnte wohl kaum aus diesen willkürlichen Likes viel über sie herausbekommen. Doch die Wissenschaft ist anderer Meinung. Michal Kosinski von der Standford-Universität hat kürzlich eine Untersuchung veröffentlicht, die beweisen soll, dass seine Computer-Algorithmen uns Menschen über die Auswertung von Facebook-Likes besser beschreiben können, als dies unsere Freunde tun können, die uns im wahren Leben sehr gut kennen. Was ist dran an dieser sehr steilen These?
Am 15.6.2015 strahlte das WDR-Fernsehen eine innovative Fernsehdokumentation zu Big Data aus, die auf witzige und experimentelle Art zeigen wollte, wie gut inzwischen Computer-Algorithmen darin sind, uns Menschen über unsere freiwillig abgegebenen Daten zu durchleuchten:
DATEN HER! Was Du im Netz wert bist… (Titel der Sendung).
Insbesondere die experimentelle Auseinandersetzung mit der Michael-Kosinski-These „Algorithmen erkennen uns besser als unsere Freunde“ (etwa ab der 5. Minute der Sendung), war spannend, weil der WDR es nicht nur geschafft hatte, den Standford-Professor Michael Kosinski zur Mitarbeit zu gewinnen; gewonnen wurden auch junge Leute, die beim Spiel mitmachten und dabei unterschiedliche Rollen übernahmen.
Facebook zur Verhaltensprognose

Michal Kosinski beim WDR
Bevor weiter auf die Sendung des WDR (DATEN HER! Was Du im Netz wert bist…) eingegangen wird, zunächst ein paar Infos zu den Hintergründen der Arbeit von Michael Kosinski. Dieser forscht schon seit Längeren zu der Frage, ob man Facebook-Likes zur psychologischen Diagnostik nutzen kann. Bereits 2013 machte er mit der steilen These auf sich aufmerksam, dass Computer aus diesen Facebook-Bewertungen grundlegende psychologische und soziologische Fakten ableiten können:
Du bist, was du magst: Aus Facebook Likes lassen sich Religion, Sexualität und Drogengebrauch vorhersagen (Überschrift eines netzpolitik.org-Artikels zur Forschungsarbeit von Michael Kosinski).
Zwar gab es Kritik an dieser sehr weitgehenden Aussage, doch die wurde überwiegend in den Kommentarspalten der Online-Medien geäußert. Die Redakteure und Blogger übernahmen die These der Vorhersagekraft der Michael-Kosinski-Algorithmen eher unkritisch, zumal sie gut ins kulturkritische Weltbild passt, gut für die Forderung nach mehr Datenschutz genutzt werden kann und insgesamt viele Vorurteile bestätigt, die man diesseits des Atlantik gegenüber den amerikanischen Internet-Großunternehmen gerne und langanhaltend pflegt.
Facebook zur Persönlichkeitsprognose
Auch die neuere Untersuchung von Michael Kosinski zu psychologischen Aussagekraft der Facebook-Likes (Englischsprache PDF mit dem entsprechenden Aufsatz) fand positive Aufnahme im deutschen Feuilleton und bei den kritischen Bloggern.
Computer-based personality judgments are more accurate than those made by humans (Titel des Aufsatzes)
Computerbasierten Persönlichkeitsurteile sind genauer als die von Menschen gemachte (Übersetzung von Google Translate)
(Ob diese Übersetzung wirklich überzeugt, kann bezweifelt werden. Auch in der WDR-Sendung wurde eher im Sinne dieser These argumentiert: Computerbasierten Persönlichkeitsurteile sind besser als die von Freunden gemachte.)
Big Five für Big Data
Man kann sich bei Süddeutsche.de über die Untersuchung zur Angemessenheit von Computer-Persönlichkeitsprofilen informieren, ohne auf die WDR-Sendung zurückzugreifen. Basis der Untersuchung ist das sehr populäre und allgemein anerkannte Big-Five-Modell der Psychologie: Es gibt genau fünf Faktoren oder Dimensionen, mit denen man Persönlichkeitsprofile messbar und vergleichbar macht:
- Neurotizismus,
- Ausprägung von Introversion bzw. Extraversion,
- Offenheit für neue Erfahrungen,
- Gewissenhaftigkeit
und schließlich als fünfte Dimension - Verträglichkeit.
Wenn man Fragebogen in der Psychologie anwendet, dann läuft das meistens darauf hinaus, so zu fragen, dass man als Befragter nicht merkt, warum es genau geht, dass aber hinterher der Befrager aus den Antworten ableitet, wie ausgeprägt man hinsichtlich der einzelnen Faktoren festgelegt ist.
Michael Kosinski befragte online mit einem entsprechenden Big-Five-Fragebogen 86.000 Facebook-Nutzer, anschließend wurden davon unabhängig Freunde der Facebook-Nutzer befragt, worauf man dann später gut ableiten kann, wie gut das Selbstbild des Facebook-Nutzers mit dem Fremdbild, das seine Freunde von ihm haben, überstimmt.
Algorithmen für Persönlichkeitsprofile auf Basis von Facebook-Likes
Ergänzend zu der Befragung der Freunde, wurde noch der Computer gefragt. Er bekam alle Facebook-Likes der ersten Gruppe (86.000 Facebook-Nutzer) und arbeitete mit einem Datenmodell, wo er die Facebook-Likes den Dimensionen der Big Five zuordnen konnte. Wie das genau geht, lässt die Süddeutsche.de (genau wie der WDR) im Dunkeln. Lediglich einige anekdotische Beispiele werden genannt, die plausibel machen sollen, wie das in etwa funktionieren könnte:
Wer angibt, gerne zu tanzen und auf Partys zu gehen, der ist vermutlich eher extrovertiert. Wer gerne wissenschaftliche Vorträge hört und neue Kunst besichtigt, ist wahrscheinlich offen für Erfahrungen. (Zitat Süddeutsche.de)

likes und korrelationen
In ähnlicher Weise greift der WDR-Beitrag zu Big Data auf Anekdotisches zurück:
Wer Weight Watchers nutzt, der lebt in einer Beziehung, wer Jennifer Lopes gut findet, der hat viele Freunde.
Hier wird wohl mehr oder weniger plausibel auf Korrelationen abgehoben, die man feststellen kann, über deren Gründe aber nichts bekannt ist. Trotzdem behauptet Michael Kosinski im WDR-Beitrag (7:20 Minute), dass es Beweise gebe, mit denen seine Computer-Algorithmen besser die Persönlichkeitsmerkmale bestimmen können als die Freunde und deshalb lässt er sich mit Optimismus auf das folgende Experiment ein. Die WDR-Autoren machen daraus dann einen Kampf „Mensch gegen Maschine“.
Zwei Männer, Zwei Frauen: Zwei Freunde, zwei Freundinnen
Der Big-Five-Fragebogen wird an zwei Personen ausgegeben, diese sollen sich nicht mit den auch anwesenden Freunden absprechen, wenn sie den Fragebogen ausfüllen. Tatsächlich werden die Freundes-Paare getrennt, die jeweiligen Freunde füllen einen eigenen Fragebogen aus. Das Ergebnis dieser Vorgehensweise: Jeweils zwei Personen füllen einen Fragebogen aus, der das Selbstbild bezüglich der Big Five misst, für diese beiden Personen gibt es aber jeweils auch ein Fremdbild eines Freundes.
Das Ausfüllen der Fragebögen wird recht ausführlich gezeigt, dadurch wird aber die Zeit knapp, mit denen man später die Ergebnisse zeigen kann. Gut ist es daher, dass man als kritischer Zuschauer bei dieser Art Fernsehsendung schnell einen Screenshot anfertigen kann, wenn mal ein relevantes Diagramm nur sehr kurz angezeigt wird.
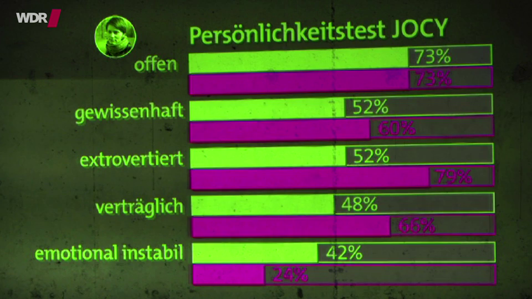
Selbstbild und Fremdbild bei den Frauern
Nun wird zunächst gezeigt, wie die Facebook-Likes an den Algorithmus ausgeliefert werden. Dann wird gezeigt, wie hoch die Übereinstimmung zwischen Fremdbild und Selbstbild ist: Steffi schätzt ihre Freundin positiver ein, als diese sich selbst. Damit an dieser Stelle von positiver die Rede sein kann, müssen die Ausprägungen der Big Five bewertet werden. Der WDR hat die Eigenschaften so aufbereitet, dass sich die obersten vier als positive Persönlichkeitsmerkmale übermittelt werden, während der fünfte und letzte Faktor eher negativ formuliert ist. Am Bild hier links sieht man, dass der violette Balken der Fremdbewertung bei den ersten vier Faktoren länger ist, beim fünften kürzer. Also ist die Aussage zutreffend, dass Steffi ihre Freundin positiver bewertet, als diese sich selber.
Nun darf Michael Kosinski dieses Ergebnis kommentieren. Auf die naheliegende Erklärung, dass Steffi ihre Freundin in der Öffentlichkeit nicht so kritisch bewerten wolle, wie diese sich selbst, kommt er nicht, möglicherweise weil er bereits darauf hofft, dass die Ergebnisse seiner Algorithmen keine so starke Abweichung vom Eigenbild ergeben werden.

Selbsbild Fremdbild Mensch und Computer Test1
Dieses Bild hier links sollte man sich etwas genauer anschauen. Die grünen Balken sind das Selbstbild, die violetten Balken sind das menschliche Fremdbild und die ockerfarbenen Balken sind das Algorithmus-Fremdbild. Ich würde das Ergebnis so interpretieren, dass die Fremdbild-Balken in etwa die gleiche Abweichung vom Eigenbild-Balken haben, allerdings in die umgekehrte Richtung: Während die Freundin durch eine positive Abweichung auffällt, zeigt der Computer-Algorithmus eher eine Tendenz zu einer negativen Bewertung. Folgt man der Einschätzung, dass ein möglichst naher Wert zur Selbsteinschätzung das qualitativ bessere Ergebnis darstellt, dann hat der Computer bei diesem Test also keinesfalls gewonnen. Die Redakteurin und die befragten Personen bleiben angesichts dieser Niederlage des Computers aber höflich und sagen, dass sie überrascht darüber sind, wie gut der Computer doch abgeschnitten habe.
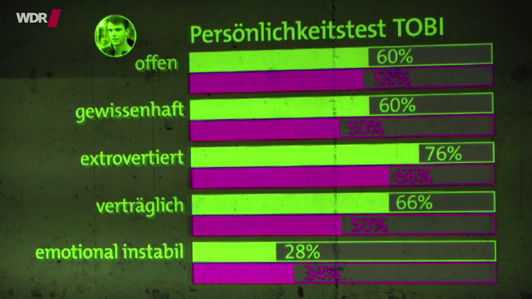
Selbstbild und Fremdbild bei den Männern
Nun kommt die zweite Variante des Tests dran. Hier zunächst die Unterschiede zwischen Selbstbild (grüne Balken) und Fremdbild (violetter Balken). Insgesamt eine ziemlich nahe Bewertung, wobei bei der männlichen Fremdbewertung offensichtlich sehr zurückhaltend vorgegangen wurde. Möglicherweise sind männliche Freunde von Männern deutlich kritischer gegenüber ihren Freunden eingestellt, als weibliche Freundinnen gegenüber ihrer Freundin.
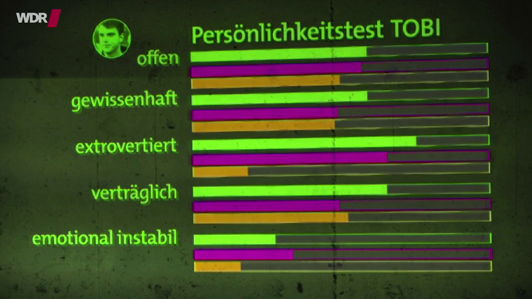
Selbsbild Fremdbild Mensch und Computer Test2
Nun wieder alle drei Balken im Vergleich. Hier ist das Ergebnis ziemlich eindeutig. Das menschliche Fremdbild stimmt besser mit dem Eigenbild überein als das Fremdbild des Computers. Während das erste Ergebnis (bei den Freundinnen) noch mit gewissen Klimmzügen wie ein Unentschieden interpretiert werden kann, ist das zweite Testergebnis eine eindeutige Niederlage des Computers, wenn man der unterstellten Einschätzung folgt, dass ein hohes Maß an Übereinstimmung von Eigenbild und Fremdbild ein qualitativ gutes Ergebnis darstellt.
Das fällt angeblich den WDR-Autoren nicht auf. Sie sagen lediglich, dass der Computer „gut rankommt, besser als bei den Frauen“. Insbesondere die letzte Einschätzung ist schwer nachvollziehbar. Als Gesamtergebnis wird dann das Gegenteil dessen festgehalten, als was tatsächlich gemessen wurde: Computer können uns leicht durchschauen.
Im WDR-Test sind die Algorithmen durchgefallen, doch das spricht nicht gegen sie
Möglicherweise ist die Untersuchung auf Basis von vielen zehntausend Versuchsteilnehmern besser für die Algorithmen von Michael Kosinski gelaufen. Doch ist das Vorgehen überhaupt angemessen, um die Leistung von Persönlichkeit-Bewertungs-Algorithmen zu bestimmen?
Psychologen sich darüber einig, dass das Selbstbild und das Fremdbild von Menschen meist unterschiedlich ausfällt. Menschen neigen dazu, sich positiver zu sehen, als die Leute, mit denen sie in Kontakt stehen. Das ist für das Überleben in einer komplizierten und gefährlichen Welt auch möglicherweise von Vorteil. Wer sich hingegen sehr kritisch sieht, möglicherweise noch kritischer als die Freunde, Verwandten und Kollegen, der steht oft in oder vor einer psychischen Belastungssituation. Menschen, die an Formen von Depression, Manie oder Bipolarer Störung leiden, haben ein zu gutes oder zu schlechtes Selbstbild und kommen deshalb zu einem Krankheitsrisiko.
Nicht legitimierbar aber ist die These, dass ein Fremdbild qualitativ besser ist, wenn es eine hohe Übereinstimmung mit dem Selbstbild hat. Eher umgekehrt: Wenn mein Eigenbild eine hohe Übereinstimmung mit dem Fremdbild hat, dass meine Freunde von mir haben, dann ist dies ein gutes Zeichen für qualitativ gute Selbsteinschätzung.
Wie Michael Kosinski hätte vorgehen müssen
Ob ein Computer-Algorithmus gut dabei ist, aus Facebook-Likes ein angemessenes Persönlichkeitsprofil abzuleiten, ist also mit dem gewählten Forschungsansatz von Michael Kosinski nicht zu bestimmen. Die steile These (Algorithmen erkennen uns besser als unsere Freunde) ist zwar nicht widerlegt, aber ist auch nicht belegt. So wie Michael Kosinski vorgegangen ist, konnte er auch diese These weder widerlegen noch bestätigen. Dazu hätte er einen anderen Forschungsansatz wählen müssen. Er hätte das Selbstbild der Probanden nicht mit dem Fremdbild des Computers konfrontieren dürfen. Er hätte besser von den einzelnen Probanden Persönlichkeitsprofile durch Experten (Psychologen) anfertigen lassen und diese Ergebnisse mit den Computer-Ergebnissen auf Basis von Facebook-Likes vergleichen können. Lägen dann die Experten und die Computer ungefähr auf dem gleichen Level oder wären sie sogar besser als die Selbstbilder der Probanden und die Fremdbilder ihrer Freunde, dann könnte man die steile These als bestätigt akzeptieren.
Allerdings kann man die Arbeit von Michael Kosinski noch retten, wenn man zu einer weniger steilen These greift: Big-Data-Algorithmen haben eine bessere Übereinstimmung mit dem Selbstbild von Facebook-Nutzern als die Fremdbild-Einschätzungen ihrer Freunde. Ein ziemlich interessantes Ergebnis, aber möglicherweise kein Ergebnis, mit dem man weitere Forschungsgelder bekommt und auch kein Ergebnis, bei der die eigene Forschungsarbeit bei Qualitätsmedien wie Süddeutsche.de und dem WDR noch beachtet wird.